While websites frequently fail to provide APIs, there's always the option of getting data from the HTML itself. This is particularly simple in PHP.
As an example, we're going to scrape the data from the Twitter hashtag for programming. Here's the link. Notice that Twitter markup is clearly generated and of especially poor quality.
We are ultimately trying to get the data and organize it ourselves.
Getting the HTML
This part is pretty easy; we just make a cURL request.
$ch = curl_init("https://twitter.com/search?q=%23programming");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$output = curl_exec($ch);
curl_close($ch);
Parsing the output
So with the presence of even a single img tag, it doesn't take a genius to figure out that this is not valid XML. Hence, SimpleXML is not an option.
We're either going to have to parse using string splitting, a giant regex (the worst method), or the preferred option - DOM.
First we create a new DOMDocument and load our HTML. We also need to supress and manually control warnings.
$document = new DOMDocument; libxml_use_internal_errors(true); $document->loadHTML($output);
Now I have to take a look at the Twitter markup to find what a typical tweet looks like in HTML. After clicking "Inspect Element" on a tweet I see that they are all in p tags with the same two classes:
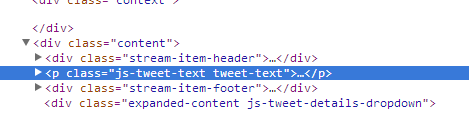
And even more conveniently for us, the js-tweet-text and tweet-text classes seem to be present if and only if a p tag is a tweet; this makes the two classes a very obvious choice for systematically fetching tweets.
So we add on our DOMXPath query:
$xpath = new DOMXPath($document);
$tweets = $xpath->query("//p[@class='js-tweet-text tweet-text']");
This returns a DOMNodeList object, which we can iterate through to display the contents of each tag. I add a little bit of formatting for readability.
echo "<html><body>";
foreach ($tweets as $tweet) {
echo "\n<p>".$tweet->nodeValue."</p>\n";
}
echo "</body></html>";
While I displayed the data as an HTML document, you can obviously output the data in whatever form you want.
Here is the entire code put together:
$ch = curl_init("https://twitter.com/search?q=%23programming");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$output = curl_exec($ch);
curl_close($ch);
$document = new DOMDocument;
libxml_use_internal_errors(true);
$document->loadHTML($output);
$xpath = new DOMXPath($document);
$tweets = $xpath->query("//p[@class='js-tweet-text tweet-text']");
echo "<html><body>";
foreach ($tweets as $tweet) {
echo "\n<p>".$tweet->nodeValue."</p>\n";
}
echo "</body></html>";
Warnings
Normally if you scrape a web page, the owner will have no idea. But if you get a little bit crazy with the web scraping (especially if you're doing so recursively or as fast as your server can manage), be prepared to be blacklisted. Of course, that can't stop you from spoofing your IP with cURL or by some other means.
Just out of courtesy, you may want to consider limiting your requests to a set number per second.
Conclusion
Hope the code is useful. Hooray! You are just like Google now.
